
整体结构
我们的应用程序通过Hadoop job client向Hadoop集群提交作业,Hadoop集群中Master节点负责调度各个Slave节点共同完成作业。
Hadoop job client是什么?
我认为有2个含义。1是在代码中使用的api,2是提交作业时使用的命令行工具。
比如在参考文章中的WordCount v1.0源代码,main方法负责构建配置并提交作业:
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
这里大部分的类都来自包org.apache.hadoop.mapreduce。
而在运行这个程序的时候,先生成jar包,再执行下面的命令:
$ bin/hadoop jar wc.jar WordCount /user/joe/wordcount/input /user/joe/wordcount/output
我们需要提供什么?
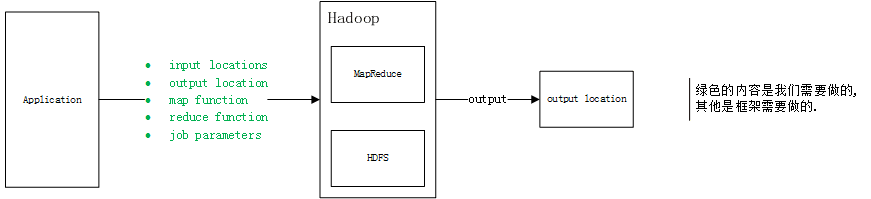
1、提供input locations和output location
上一篇:金融行业大数据之风控 下一篇:防火墙的参数及选择标准














